Abstract
Multimodal Large Language Models (MLLMs) have demonstrated strong generalization in vision-language tasks, yet their ability to understand and act within embodied environments remains underexplored. We present NavBench, a benchmark to evaluate the embodied navigation capabilities of MLLMs under zero-shot settings. NavBench consists of two components: (1) navigation comprehension, assessed through three cognitively grounded tasks including global instruction alignment, temporal progress estimation, and local observation-action reasoning, covering 3,200 question-answer pairs; and (2) step-by-step execution in 432 episodes across 72 indoor scenes, stratified by spatial, cognitive, and execution complexity. To support real-world deployment, we introduce a pipeline that converts MLLMs' outputs into robotic actions. We evaluate both proprietary and open-source models, finding that GPT-4o performs well across tasks, while lighter open-source models succeed in simpler cases. Results also show that models with higher comprehension scores tend to achieve better execution performance. Providing map-based context improves decision accuracy, especially in medium-difficulty scenarios. However, most models struggle with temporal understanding, particularly in estimating progress during navigation, which may pose a key challenge.
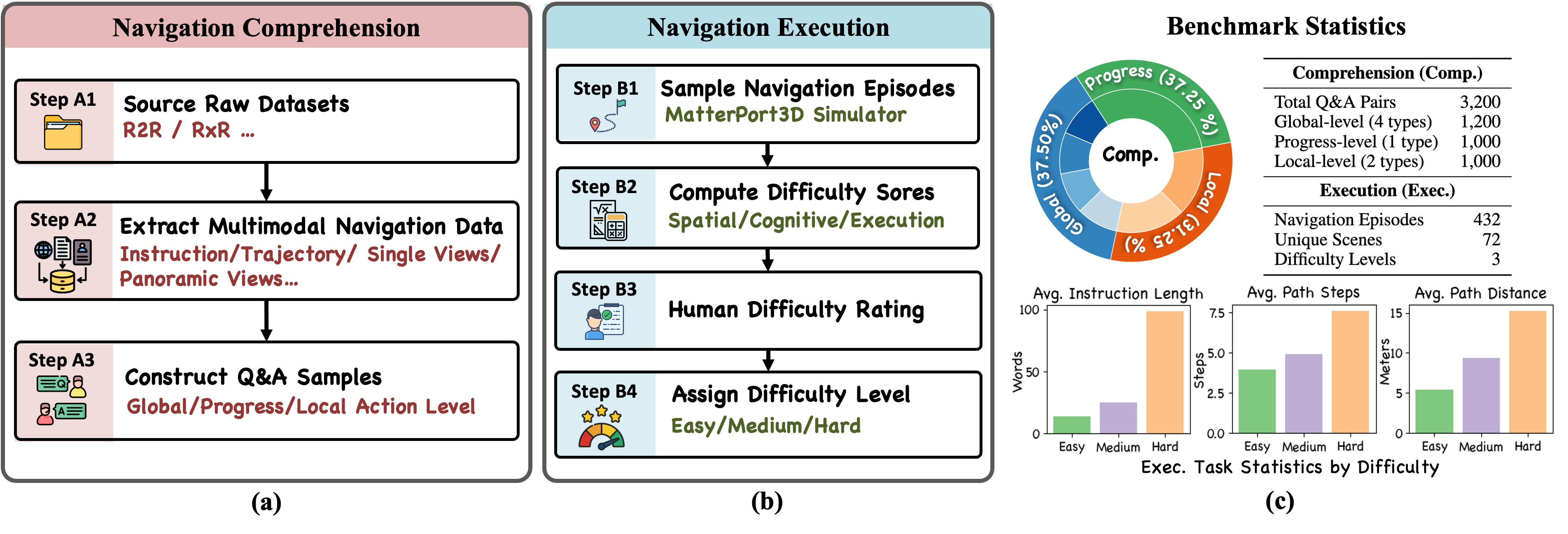
NavBench construction pipeline and statistics.
(a) QA generation for comprehension tasks at global, progress, and local levels.
(b) Execution pipeline combining automatic difficulty scoring and human ratings.
(c) Benchmark statistics, including comprehension (comp.) task distribution, QA counts, and execution statistics (e.g., instruction length, steps, distance).
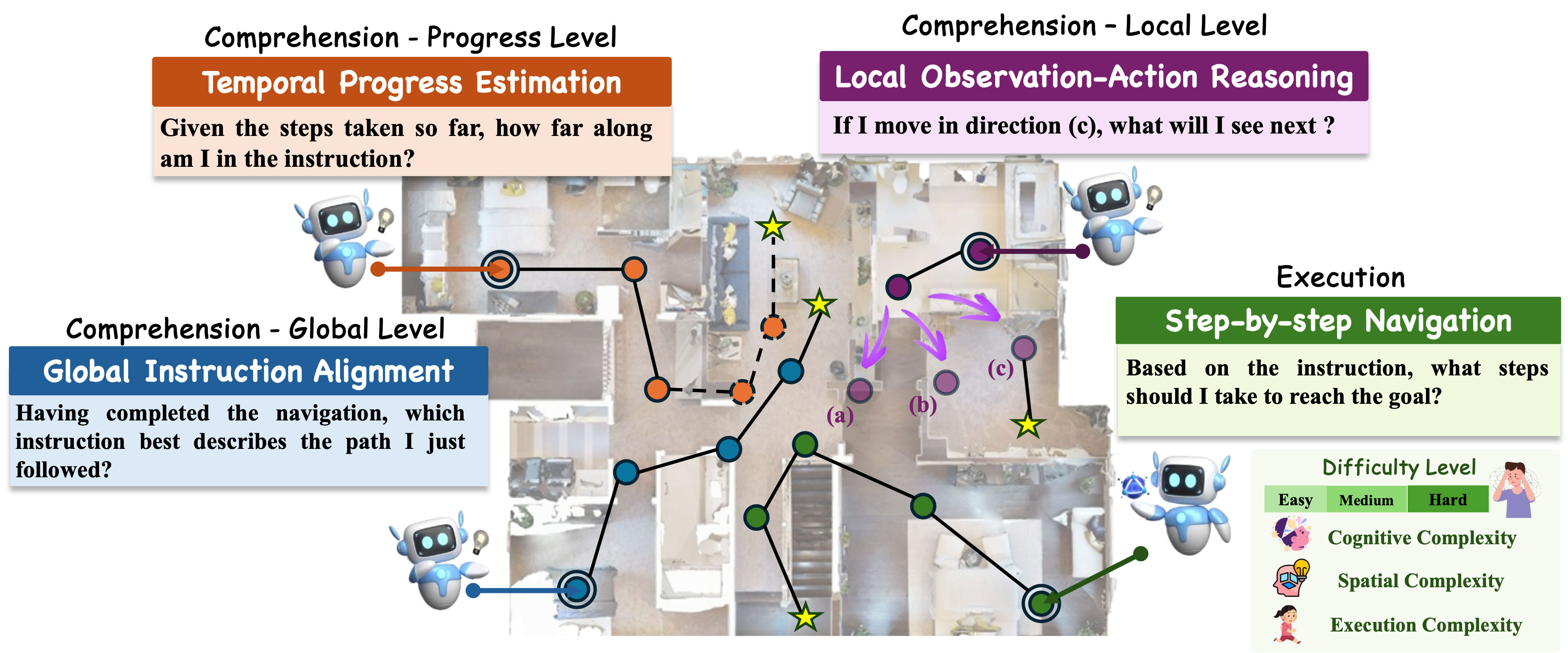
Global Instruction Alignment Examples
Example 1

You are presented with a sequence of panoramic views that represent a navigation path from the starting point to the goal location. Identify the correct instruction.
Example 2

You are presented with a sequence of panoramic views that represent a navigation path from the starting point to the goal location. Identify the correct instruction.
Temporal Progress Estimation Examples
Example 1

You are given a navigation instruction divided into multiple sub-instructions, along with a trajectory. Your task is to determine how many sub-instructions have been completed based on the views provided.
Example 2

You are given a navigation instruction divided into multiple sub-instructions, along with a trajectory. Your task is to determine how many sub-instructions have been completed based on the views provided.
Local Observation-Action Reasoning Examples
Example 1


Example 2


Real-world Embodied Navigation Pipeline

Overview of the real-world embodied navigation pipeline, demonstrating how MLLMs can be integrated into physical navigation systems.
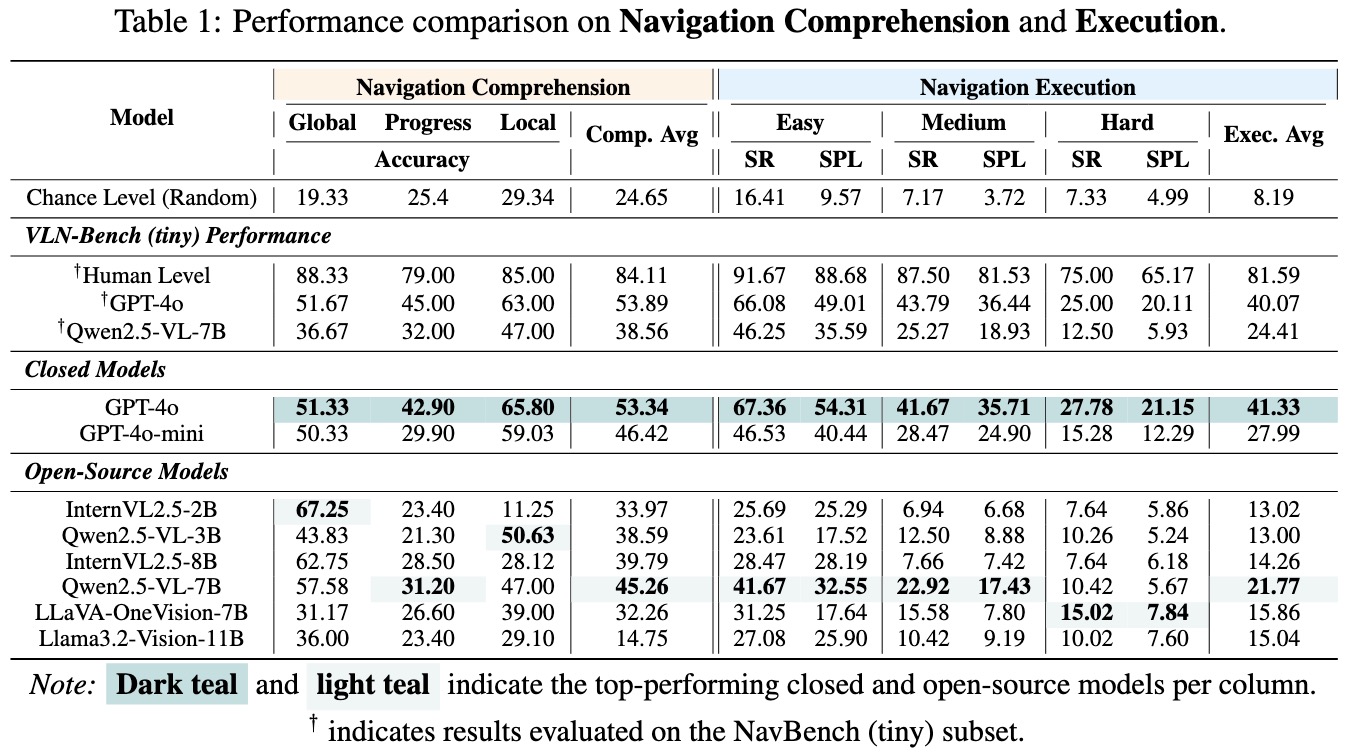
Results
BibTeX
@article{qiao2025navbench,
title={NavBench: Probing Multimodal Large Language Models for Embodied Navigation},
author={Qiao, Yanyuan and Hong, Haodong and Lyu, Wenqi and An, Dong and Zhang, Siqi and Xie, Yutong and Wang, Xinyu and Wu, Qi},
journal={arXiv preprint arXiv:2506.01031},
year={2025}
}